|
Itamar Zimerman I am a PhD candidate in the Blavatnik School of Computer Science at Tel Aviv University, advised by Prof. Lior Wolf. Additionally, I work as an AI research scientist at IBM Research. |

|
ResearchMy research focuses on modern deep learning architectures, with a particular emphasis on improving their capabilities in language modeling, computer vision, and crypto applications. I am passionate about developing architectures and understanding their design principles, especially transformers, state-space layers and modern RNNs. Selected PublicationsRepresentative papers are highlighted. '*' indicates equal contribution. |
|
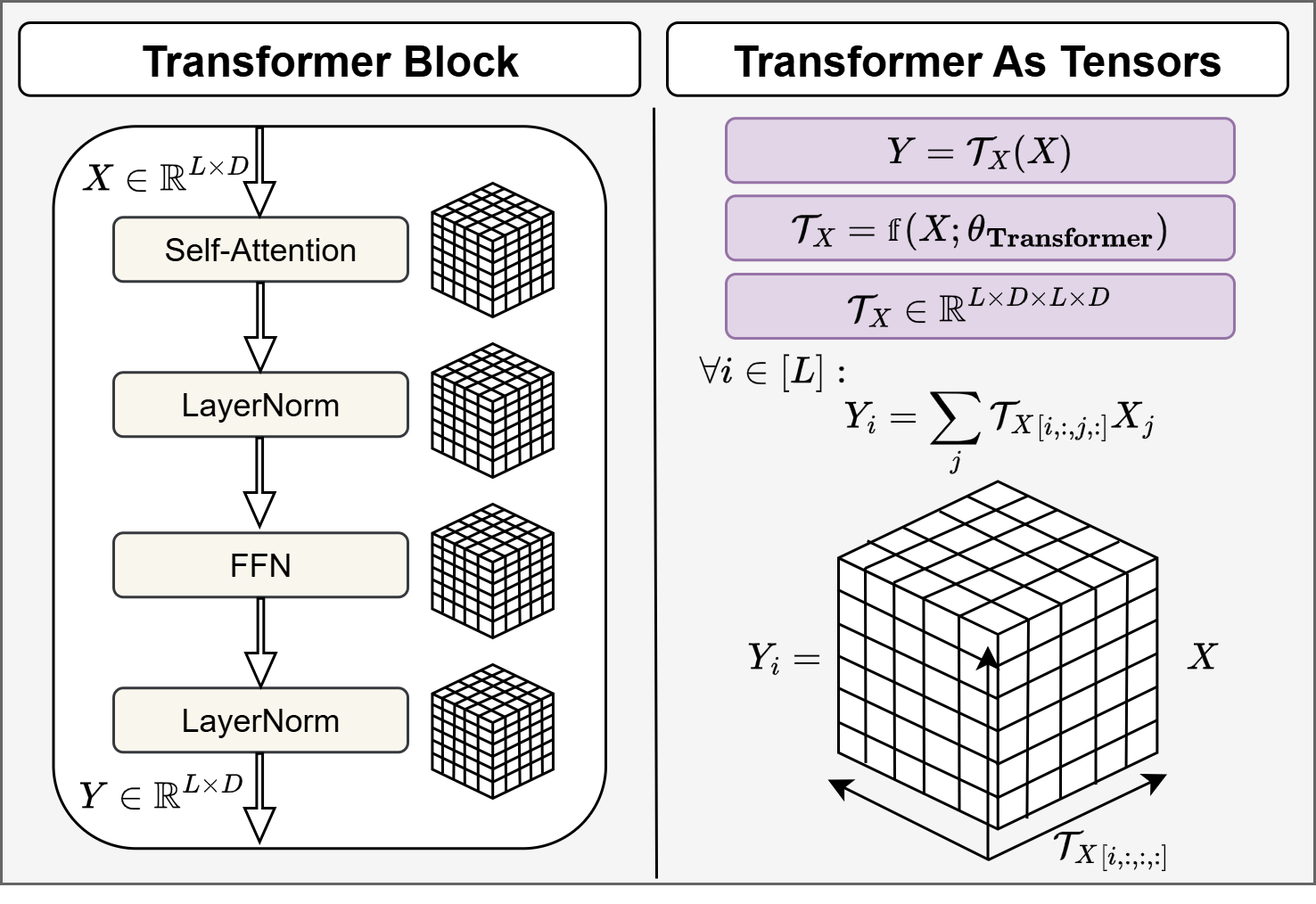
TensorLens: End-to-End Transformer Analysis via High-Order Attention Tensors
I. Atad, I. Zimerman, S. Katz, L. Wolf We introduce TensorLens! A tensor algebra based reformulation of Transformers as a single input-dependent high order attention tensor that generalizes attention matrices in two ways: (i) it can include FFNs, embeddings, and any part of the computational graph, and (ii) it is modular, so it can aggregate any Transformer circuit (specific heads, subsets of layers, and more) into a single tensor. Empirically, we found that TensorLens reflects model behavior better than attention matrices and prior aggregation methods, and it has practical interpretability applications such as linear relation decoding. arXiv, 2026 |

|
Overclocking LLM Reasoning: Monitoring and Controlling Thinking Path Lengths in LLMs
R. Eisenstadt, I. Zimerman, L. Wolf We show that LLMs internally track their progress during explicit reasoning. By identifying this thinking progress signal, we leverage it to monitor reasoning with an interactive progress bar and to control the thinking length by overclocking (shortening) it. Our method improves DeepSeek-R1 in both efficiency and effectiveness by enforcing more decisive thinking. Finally, our work sheds light on the planning abilities and self-regulation mechanisms of LLMs. arXiv, 2025 |
|
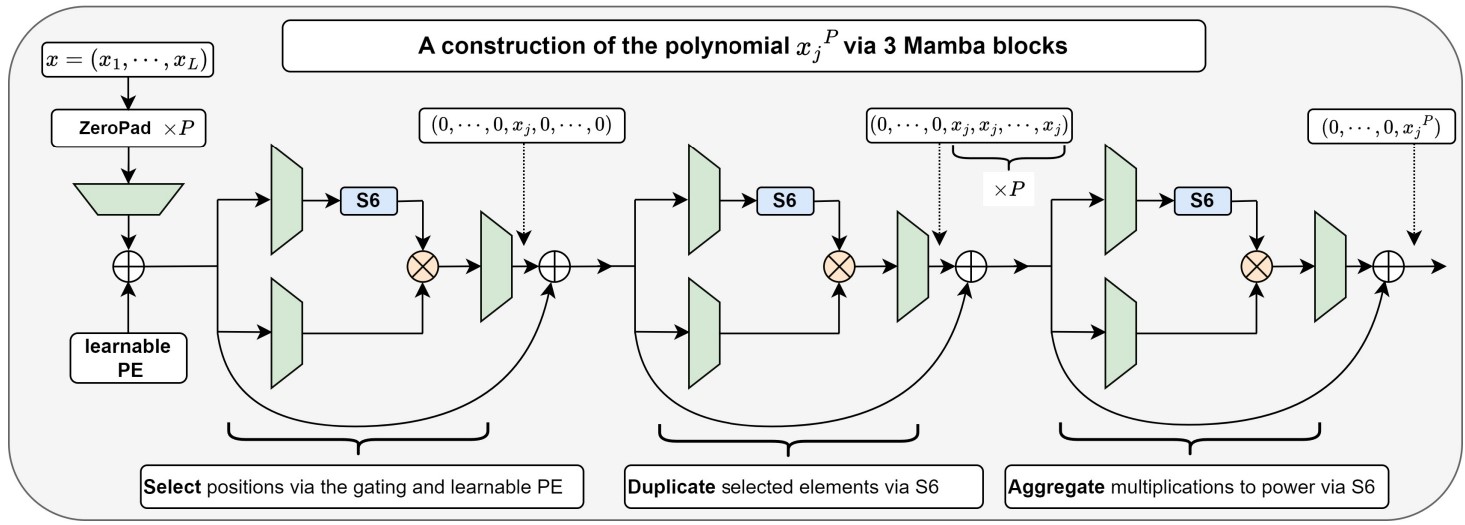
On the Expressivity of Selective State-Space Layers: A Multivariate Polynomial Approach
E. Cohen-Karlik*, I. Zimerman*, L. Galanti*, I. Atad, A. Globerson, L. Wolf We investigate the expressivity of Mamba compared to Transformers via multivariate polynomials and show the theoretical advantages of the Mamba layer. While the expressivity is higher, especially for long sequences, we show that this does not come at the expense of generalization. AISTATS, 2026 |
|
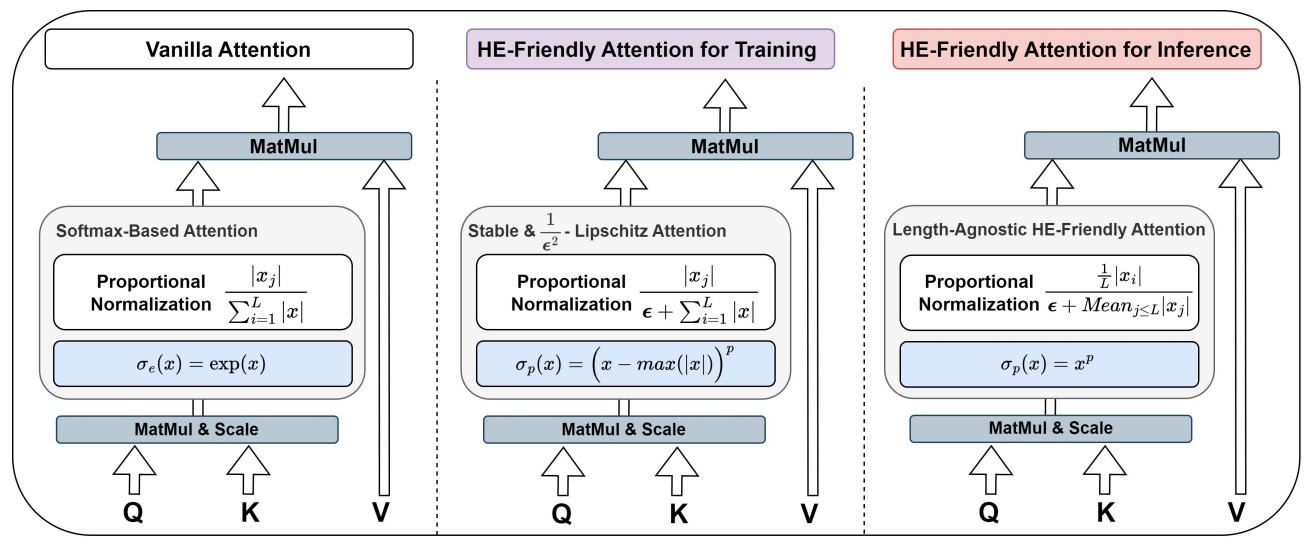
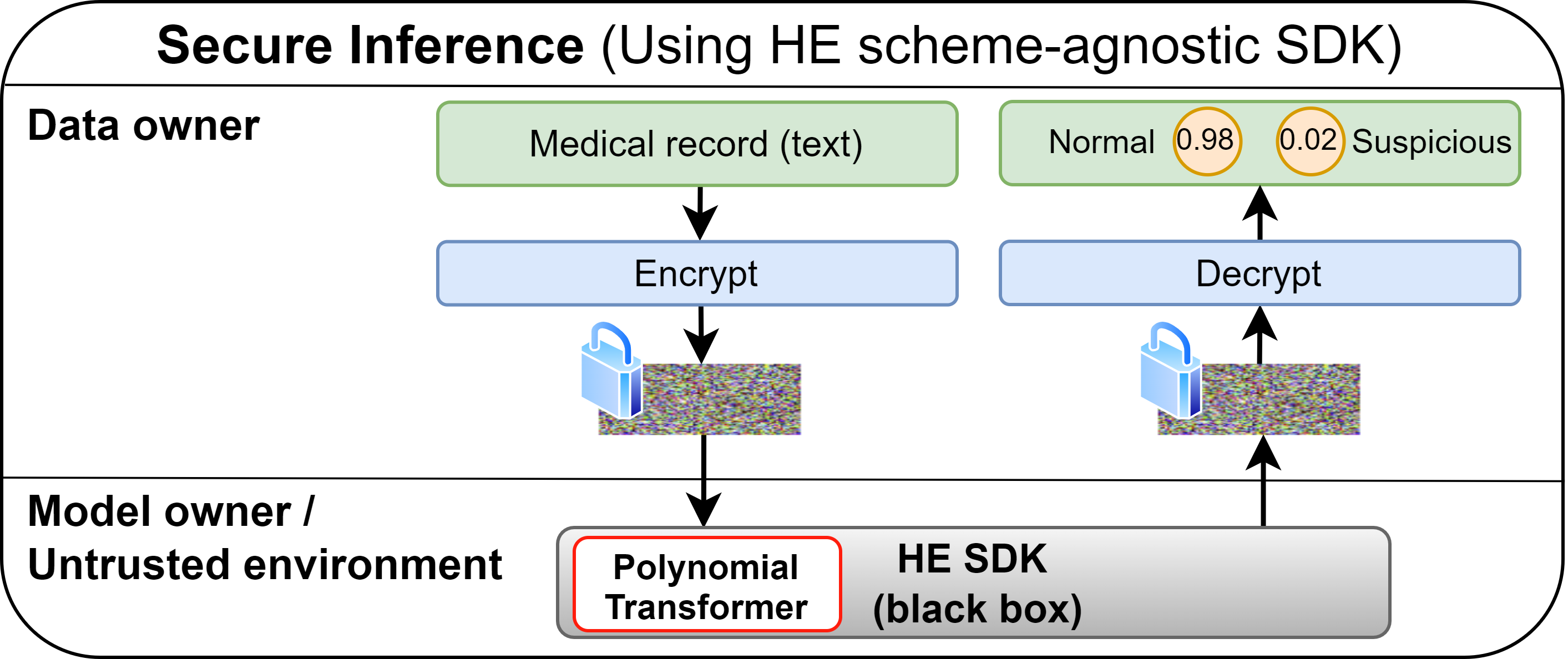
Power-Softmax: Towards Secure LLM Inference over Encrypted Data
I. Zimerman, A. Adir, E. Aharoni, M. Avitan, M. Baruch, N. Drucker, J. Lerner, R. Masalha, R. Meiri, O. Soceanu We introduce PowerSoftmax, an HE-friendly self-attention mechanism that enables fully polynomial transformers for scalable secure inference with Homomorphic Encryption (HE). Our method enables the first polynomial LLMs with 32 layers and 1.4 billion parameters, achieving strong reasoning and in-context learning (ICL) capabilities. This work advances the field of privacy-preserving LLM inference. AISTATS, 2026 |

|
Revisiting LRP: Positional Attribution as the Missing Ingredient for Transformer Explainability
Y. Bakish, I. Zimerman, H. Chefer, L. Wolf Attribution methods that assign relevance to tokens are key to extracting explanations from Transformers and LLMs. However, we obsrve that existing approaches often produce fragmented and unstructured heatmaps because they do not propagate attribution through positional encodings (PE). To address this, we propose PE-Aware LRP, which reformulates the input space of the XAI problem as token-position pairs and introduces theoretically grounded LRP rules for PE components such as Rotary. NeurIPS, 2025 |
|
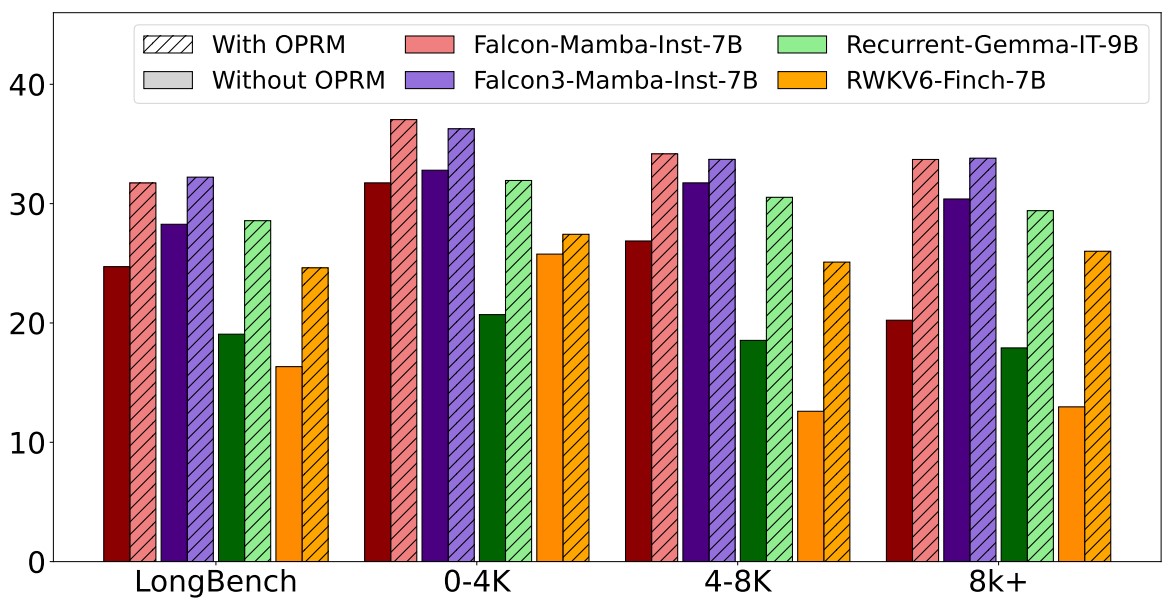
Overflow Prevention Enhances Long-Context Recurrent LLMs
A. Ben-Kish, I. Zimerman, M. Jehanzeb Mirza, J. Glass, L. Karlinsky, R. Giryes While recurrent LLMs such as Falcon-Mamba designed for long-context efficiency, we find their effectiveness remains limited due to memory overflows. To address this, we introduce a simple chunk-based inference method that selects only the most relevant input segment, improving performance by 28 to 51 % on LongBench and achieving SoTA results on LongBench v2, outperforming Transformers of similar size. These findings provide a clearer view of the actual performance of leading LLMs and highlight the surprising strength of a single well-chosen chunk. COLM, 2025 |
|
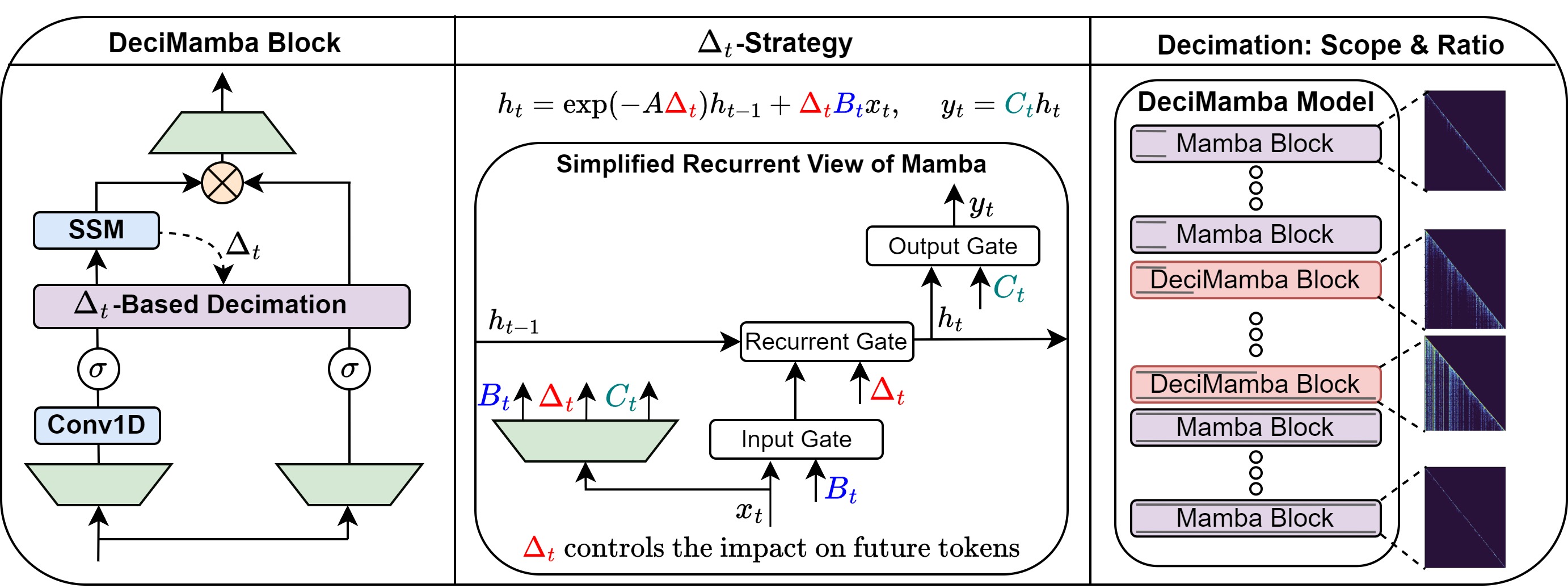
DeciMamba: Exploring the Length Extrapolation Potential of Mamba
A. Ben-Kish, I. Zimerman, S. Abu-Hussein, N. Cohen, A. Globerson, L. Wolf, R. Giryes We investigate the length-extrapolation capabilities of Mamba models, revealing their limited effective receptive field. To address these limitations, we introduce DeciMamba, the first context-extension method specifically designed for Mamba. Empirical experiments on real-world long-range NLP tasks demonstrate that DeciMamba can extrapolate to context lengths up to 25 times longer than those encountered during training. ICLR, 2025 |
|
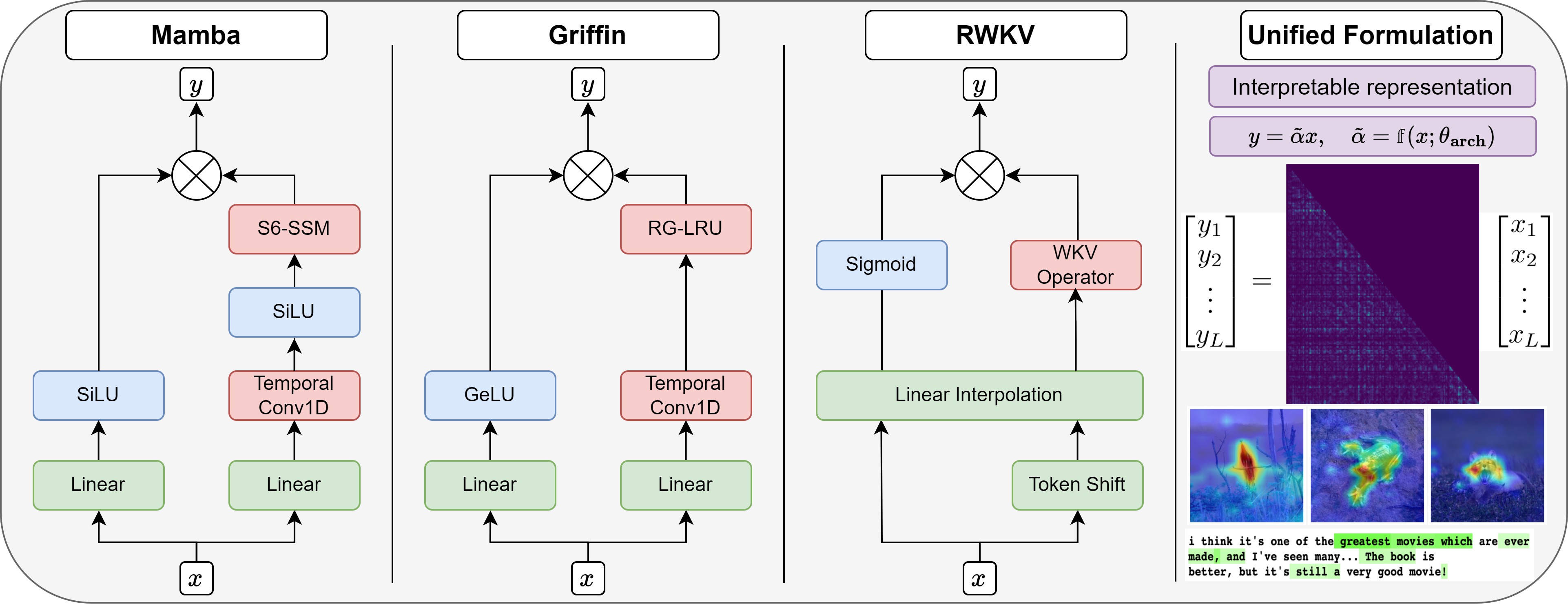
Explaining Modern Gated-Linear RNNs via a Unified Implicit Attention Formulation
I. Zimerman*, A. Ali*, L. Wolf We introduce a unified representation of attention-free layers, including Mamba, RWKV, RetNet, and Griffin, using an implicit self-attention formula. Our approach is more comprehensive and precise than previously proposed frameworks, and it significantly enhances the interpretability and explainability of these models. ICLR, 2025 |

|
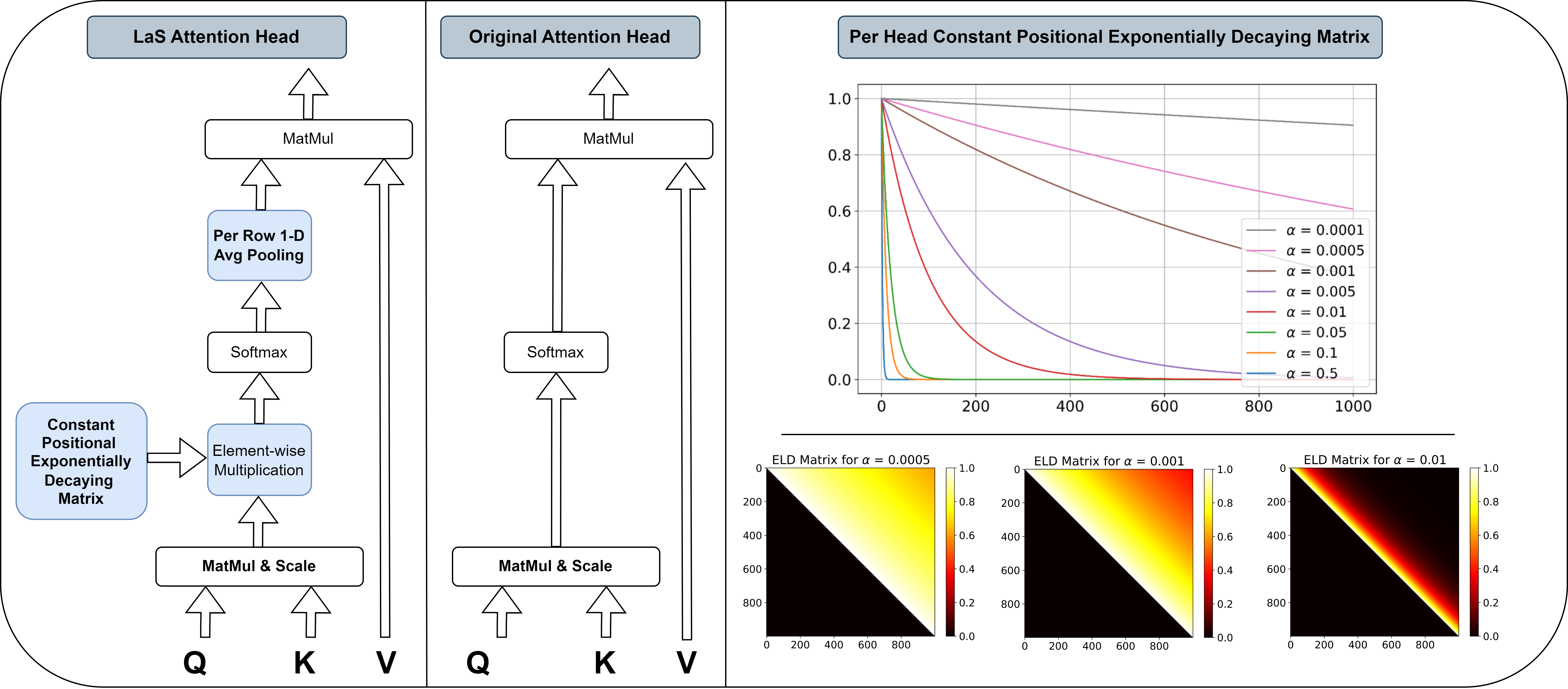
The Hidden Attention of Mamba Models
A. Ali*, I. Zimerman*, L. Wolf We establish the connection between S6 layers and causal self-attention, demonstrating that both rely on a data-control linear operator, which can be represented through attention matrices. Using these matrices, we introduce the first explainability tools for Mamba models. ACL, 2025 (Main Conference) |
|
Viewing Transformers Through the Lens of Long Convolutions Layers
I. Zimerman, L. Wolf We investigate the design principles that enable long-range layers, such as state-space models and Hyena, to outperform transformers on long-range tasks. ICML, 2024 |
|
Converting Transformers to Polynomial Form for Secure Inference Over Homomorphic Encryption
I. Zimerman, M. Baruch, N. Drucker, G. Ezov, O. Soceanu, L. Wolf We introduce the first polynomial transformer, which is based on a novel alternative to softmax and layer normalization. This breakthrough enables the application of transformers on encrypted data for the first time. ICML, 2024 |
|
A 2-Dimensional State Space Layer for Spatial Inductive Bias
E. Baron*, I. Zimerman*, L. Wolf 2D-SSM is a spatial layer that extends S4 into multi-axis data and is parametrized by 2-D recursion. Empirically, it enhances the performance of various ViTs and ConvNeXt backbones. Theoretically, our layer is more expressive than previous extensions. ICLR, 2024 |

|
Multi-Dimensional Hyena for Spatial Inductive Bias
I. Zimerman, L. Wolf We present Hyena N-D, a theoretically grounded extension of the Hyena layer to multi-axis sequence modeling. We show that when incorporated into a ViT instead of an attention mechanism, it results in a data- and memory-efficient model. AISTATS, 2024 |
|
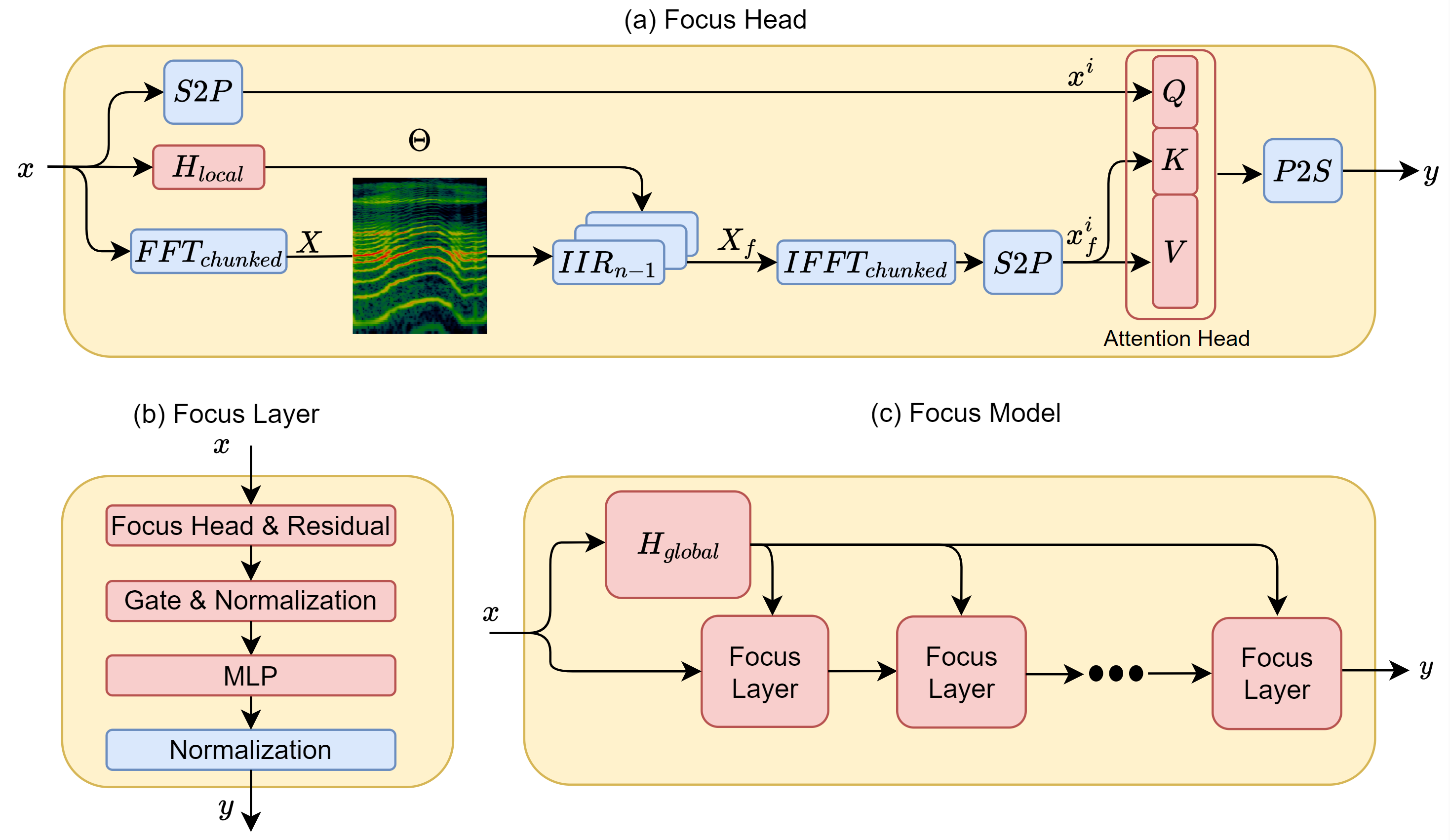
Focus Your Attention (with Adaptive IIR Filters)
S. Lutati, I. Zimerman, L. Wolf Focus is a new architecture for LMs built on adaptive IIR filters. We show that second-order IIR filters are theoretically more expressive than state-space models, yet still stable. We boost the performance of these filters by making them adaptive, with the first global-convolution-based hypernetwork. EMNLP, 2023 (Oral presentation) |
|
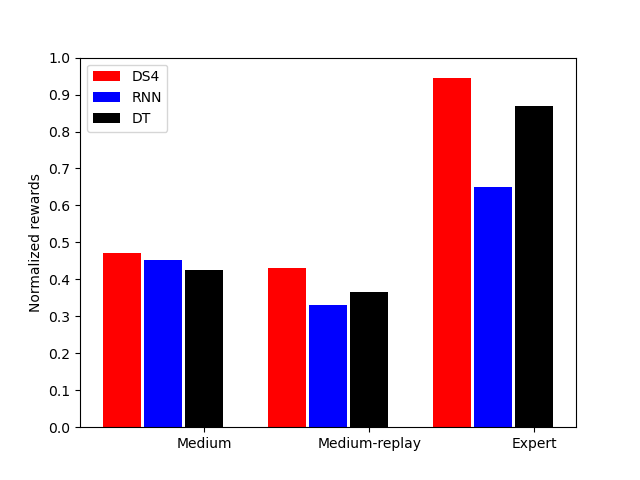
Decision S4: Efficient Sequence-Based RL via State Spaces Layers
S. Bar-David*, I. Zimerman*, E. Nachmani, L. Wolf We explore the application of the state-space layers in offline and online RL, highlighting its superiority in handling long-range dependencies and its improved efficiency over transformers. ICLR, 2023 |

|
Recovering AES Keys with a Deep Cold Boot Attack
I. Zimerman*, E. Nachmani*, L. Wolf Here we present a DL-based side-channel attack on AES keys. Our method combines a SAT solver with neural tools from the field of error correction coding to enhance attack effectiveness. ICML, 2021 |
|
This page design is based on a template by Jon Barron. |